
У світі iOS-розробки є всім відома бібліотека JSQMessagesViewController, яка допомагає iOS-розробникам без особливих зусиль реалізувати UI чату у своїх додатках. На жаль, Android-розробники позбавлені такого чудового інструменту. Тому ми поставили собі за мету надати розробникам Android широкі можливості для створення швидкого і привабливого користувацького інтерфейсу для чатів у своїх додатках.
ChatKit - це бібліотека, призначена для спрощення розробки користувальницького інтерфейсу для такого тривіального завдання, як чат. Бібліотека має гнучкі можливості для стилізації, налаштувань і керування даними.
Особливості:
- Готове до вживання, тобто вже розроблене рішення для швидкої реалізації;
- Повністю настроювані макети - встановлення стилів із коробки (використовуйте власні кольори, текстові зображення, розтяжки, селектори та розміри) або ж створення власної користувацької розмітки та/або холдерів для унікальної поведінки;
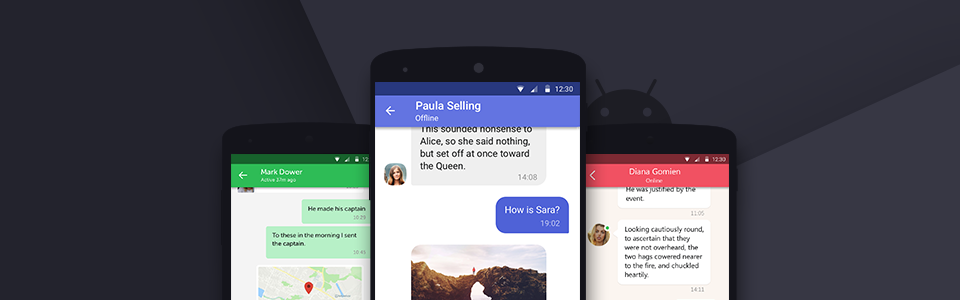
- Список діалогів, включно з тет-а-тет і груповими чатами, маркерами для непрочитаних повідомлень і переглядом останніх повідомлень користувача;
- Список повідомлень (вхідних і вихідних) з посторінковою хронологією і вже розрахованими заголовками дат;
- Різні аватари без конкретної реалізації завантаження зображень - ви можете використовувати будь-яку бібліотеку на свій смак;
- Режим вибору для взаємодії з повідомленнями;
- Легке форматування дат;
- Ваші власні моделі для діалогів і повідомлень. Конвертації не потрібно;
- Готове до використання подання введення повідомлень;
- Користувацькі анімації (відповідно до використання RecyclerView).
Для реалізації чату розробнику надається три компоненти:
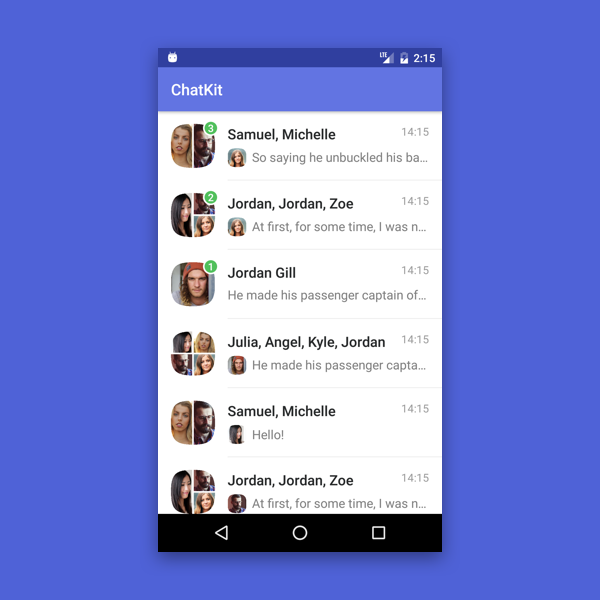
1. DialogsList
Компонент для відображення та керування списком діалогів. Основні функції: швидка і проста реалізація, підтримка діалогу тет-а-тет і груповий діалог, маркери непрочитаних повідомлень. Також існує кілька методів налаштування для зміни зовнішнього вигляду списку діалогів і реалізації додаткових функцій, які за замовчуванням не ввімкнені.
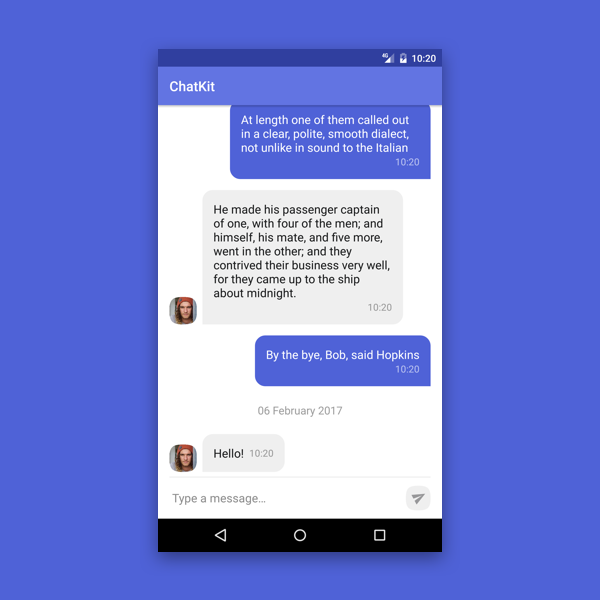
2. MessageList
Це компонент для відображення та керування повідомленнями в розмові. Його основною особливістю є правильна і проста взаємодія зі списком повідомлень і заголовком дати, який реалізується через адаптер. Крім того, він підтримує кілька рівнів налаштування, що дають змогу додавати всі функції, які не були включені за замовчуванням.
3. MessageInput
MessageInput є допоміжним компонентом для введення текстових повідомлень, він підтримує просту перевірку і обробляє всі стани кнопки "відправити". Крім того, він підтримує достатньо атрибутів для стилізації зовнішнього вигляду.
У всіх компонентів є можливість стилізації за допомогою xml-атрибутів.
За допомогою атрибутів у DialogsList ми можемо змінювати окремо для прочитаних і непрочитаних діалогів: колір фону елемента списку, розмір шрифту, колір і стиль тексту для заголовка діалогу, останнього повідомлення, дати останнього повідомлення. А також розміри аватара діалогу і розміри аватара автора повідомлення (тільки для групових чатів), налаштування роздільника між елементами (зовнішній вигляд, колір, відступи).
Атрибути в MessageList дають нам змогу встановити колір фону за замовчуванням для вхідних і вихідних повідомлень, і навіть кольори для їхніх станів "натиснуто" і "вибрано". Ми також можемо змінити колір і розмір шрифту повідомлення, тексту часу надсилання і заголовка.
Використовуючи доступні атрибути віджета MessageInput, ми можемо змінити колір і розмір тексту та підказки введення, максимальну кількість дозволених рядків, розмір і відступ кнопки "відправити", а також її значок і фон.
Але що, якщо вам потрібно не тільки змінити зовнішній вигляд елементів, а й їхнє положення? Це не має значення, тому що ви можете створити свій власний макет! Єдина умова - ідентифікатори елементів повинні відповідати ідентифікаторам за замовчуванням, а типи віджета не повинні викликати виняток класу ClassCastException (тобто, бути того ж типу або типом підкласу).
Приклад кастомізації зміни макета MessageList:
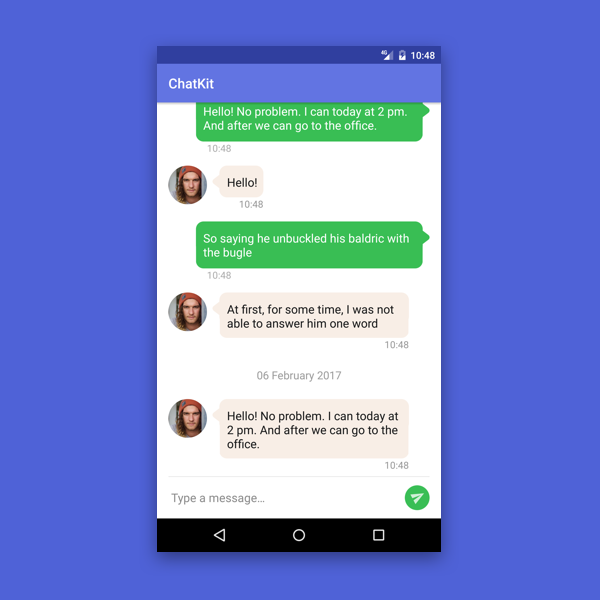
Іноді відображення тексту повідомлення недостатньо. Наприклад, вам потрібно додати статус обробки повідомлення та реакцію на повідомлення (як у Slack). Звичайно, для цього вам потрібно створити свій власний макет, але ви не можете це зробити без зміни логіки ViewHolder. Тому в нашій бібліотеці є можливість використання свого власного ViewHolder для елементів.
Ознайомитися з документацією і подивитися приклади використання даного рішення ви можете на нашій GitHub-сторінці бібліотеки.


